







































FLoC Là Gì? Kế Hoạch Của Google Để Loại Bỏ Cookies Của Bên Thứ Ba
Tiếp nối Flash, các cookies của bên thứ ba (third-party cookies) đã bắt đầu bị loại bỏ bởi các trình duyệt như Safari hay Firefox, và bây giờ, là đến lượt Google.

Google đã lên kế hoạch chấm dứt hỗ trợ cookies của bên thứ ba trên trình duyệt Chrome vào năm 2022, và họ đã tạo ra dự án Privacy Sandbox (https://www.chromium.org/Home/chromium-privacy/privacy-sandbox) với mục tiêu tạo ra một hệ sinh thái web tôn trọng người dùng và đề cao tính bảo mật để thử nghiệm các ý tưởng mới và tiếp thu những đánh giá phản hồi. Các quyết định làm ảnh hưởng đến Chrome – với gần 2/3 thị phần – cũng chính là các quyết định ảnh hưởng đến thế giới Internet, nhất là đối với hoạt động quảng cáo trả phí (paid advertising).

(Nguồn: Internet)
Nhưng vẫn còn thời gian để Google tìm ra cách bảo vệ đế chế quảng cáo của họ mà không cần quyền truy cập vào dữ liệu của người dùng – điều đã từng khiến cho nền tảng này trở nên sinh lời đến vậy. Giải pháp này phải cân bằng được bốn yếu tố sau đây:
- Doanh thu cho các đơn vị xuất bản (publisher) bán không gian quảng cáo (ad space);
- Khả năng nhắm mục tiêu (targeting capability) cho các mạng quảng cáo (ad networks);
- Lợi nhuận trên khoảng chi tiêu quảng cáo (return on ad spend) cho những người mua quảng cáo (ad buyers);
- Tính bảo mật/riêng tư (privacy) cho những người dùng nhìn thấy quảng cáo.
Ba yếu tố đầu tiên sẽ đi chung với nhau – nếu các nhà quảng cáo có thể đo lường và có được lợi nhuận tốt trên chi phí đã bỏ qua, họ sẽ tiếp tục bỏ tiền cho quảng cáo. Các nền tảng quảng cáo sẽ tiếp tục bán “inventory” (thuật ngữ chỉ không gian quảng cáo được cung cấp cho các đơn vị mua). Các nhà xuất bản sẽ tiếp tục thu được doanh thu từ quảng cáo.
Nhưng việc loại bỏ đi cookies sẽ không cải thiện khả năng nhắm mục tiêu của quảng cáo. Mà sẽ làm nó kém hiệu quả hơn. Câu hỏi ở đây đó là: Liệu Google có thể phát triển một hệ thống mới để giữ cho những người mua quảng cáo tiếp tục chi tiền nếu những người dùng giờ đây sẽ là các đối tượng ẩn danh không? Hãy cùng Đào tạo Digital Marketing Á Âu tìm hiểu qua bài viết chi tiết này nhé!
Cookies của bên thứ ba không ảnh hưởng đến tất cả mọi thứ
Cookies của bên thứ ba (third-party cookies) là “xương sống” của hoạt động quảng cáo hiển thị (display advertising), nhưng chúng không phải là cách thức duy nhất mà website thu thập data của người dùng.
Đối với cookies của bên thứ nhất (first-party cookies) thì không có gì thay đổi. First-party cookies được thiết lập bởi một website khi bạn truy cập nó. Người dùng có thể chặn các first-party cookies này, nhưng làm thế thường ảnh hưởng đến trải nghiệm người dùng (chẳng hạn như xóa đi những sản phẩm mà bạn đang để trong giỏ hàng, hay buộc bạn phải đăng nhập lại một lần nữa…).
Còn cookies của bên thứ ba (third-party cookies) thì được thiết lập bởi một đơn vị khác (ví dụ như một nền tảng quảng cáo) và có thể được truy cập ở bất cứ địa chỉ mà đoạn code của họ tải xuống. Chúng tổng hợp nhiều dữ liệu hơn ngoài các lượt click của bạn trên Internet và tận dụng nó để cung cấp cho các quảng cáo siêu-liên-quan mà bạn nhìn thấy (ví dụ như một mẩu quảng cáo cho một ản phẩm mà bạn đã bỏ trong giỏ hàng trên một website khác).
Hiểu một cách đơn giản hơn, thì các bên theo dõi thứ ba (third-party tracker) có thể theo dõi hành vi của một người dùng, chẳng hạn như content mà họ xem trên website đó và những thứ mà họ nhấp vào (các sản phẩm, quảng cáo…). Bên theo dõi sẽ tạo ra các third-party cookies và sử dụng chúng để hiển thị các quảng cáo đến người dùng khi họ truy cập vào các website khác.
Ví dụ, nếu người dùng truy cập vào website A và nhấp vào một sản phẩm, thì các bên theo dõi thứ ba sẽ thu thập và phân tích những thông tin về người dùng đó cũng như các hoạt động của họ trên website A. Sau đó, nếu người dùng trên rời khỏi trang A và truy cập vào một website khác, chẳng hạn website B, thì người dùng có thể được hiển thị một quảng cáo cho chính xác sản phẩm đó hoặc một nội dung gì đó tương tự (ví dụ như một chiếc TV khác hoặc một sản phẩm điện tử khác…).
Cách thức hoạt động ở đây đó là cả website A và website B đều load một đoạn code từ một máy chủ quảng cáo (ad server) C. Khi người dùng đó điều hướng đến website nào, thì đoạn mã được tải xuống từ server C cũng là tài nguyên đến từ một domain khác – không phải là địa chỉ URL trong trình duyệt của người dùng, vậy nên cookies được thiết lập trong địa chỉ C được xem như là third-party cookies.
Các động cơ để chặn third-party cookies là rất cao – hậu quả duy nhất thực sự đó là bạn sẽ thấy ít quảng cáo có liên quan hơn. Nhưng nếu không có các third-party cookies, thì một mạng lưới hiển thị (display network) sẽ phải làm gì?
FLoC cố gắng giải quyết một vấn đề đơn giản hơn — nhắm mục tiêu dựa trên sở thích (interest-based targeting)
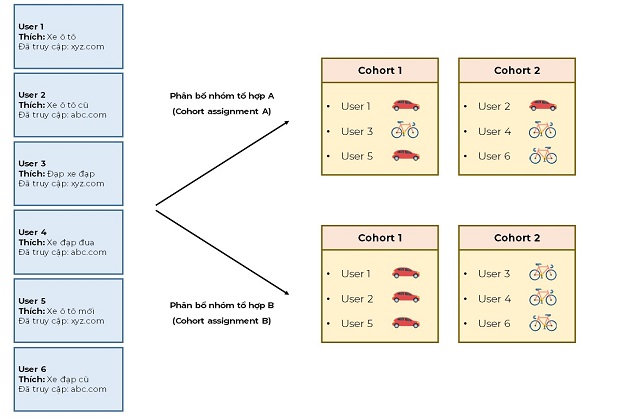
Các ad network có 3 cách để quyết định xem sẽ hiển thị quảng cáo nào:
- Sử dụng các thông tin ngữ cảnh và thông tin của bên thứ nhất (first-party & contextual information); ví dụ như “đặt quảng cáo này trên các web page nói về xe mô tô”.
- Sử dụng các thông tin chung về những sở thích của người dùng sẽ xem quảng cáo đó; ví dụ “hiển thị quảng cáo này cho những người yêu thích nhạc cổ điển”.
- Sử dụng những hành động cụ thể mà người dùng đã thực hiện trước đó; ví dụ “giảm giá cho một số mẫu giày mà họ đã bỏ trong giỏ hàng”.
Nhiều website hiện đang không khai thác tối ưu những first-party cookies của họ, việc khắc phục đó nên được ưu tiên. Còn cách thức thứ 3 ở trên hiện đang được xử lý thông qua TURTLEDOVE và những chương trình có liên quan (sẽ được trình bày cụ thể hơn ở phần sau).
Federated Learning of Cohorts hay FLoC (tạm dịch: Công nghệ học tập nhóm tổ hợp có liên kết, xem thêm tại https://github.com/WICG/floc) là một thuật toán máy học cho phép các thiết bị cộng tác (collaborate) để học một mô hình dự đoán trong khi vẫn giữ toàn bộ dữ liệu đào tạo trên thiết bị.
Trong số 3 cách ở trên, thì FLoC thuộc nhóm thứ 2. Nó được xem là một giải pháp thay thế cho third-party cookies. Nếu như cookies sẽ theo dõi và thu thập lịch sử hành vi của từng cá nhân thì FLoC cũng sẽ ghi nhận những hành vi đó và đưa nó vào một nhóm tổ hợp (cohort) gồm nhiều đối tượng cũng có sở thích như vậy, nhưng những dữ liệu này sẽ không được chia sẻ với Google.
Các nhóm tổ hợp này sẽ là nền tảng vừa đủ để các nhà quảng cáo hiển thị các quảng cáo phù hợp, nhưng vẫn có tính bảo mật, không quá chi tiết để các nhà quảng cáo không nhận diện được các đối tượng có trong nhóm đó.
Cơ chế hoạt động của FLoC
Ý tưởng cốt lõi đằng sau FLoC đó là “ẩn” đi các cá nhân “giữa đám đông”. Bước đột phá công nghệ, được công bố vào năm 2017, chính là thành phần “liên kết” (federated) – là khả năng huấn luyện một mô hình học máy mà không cần kho dữ liệu tập trung:
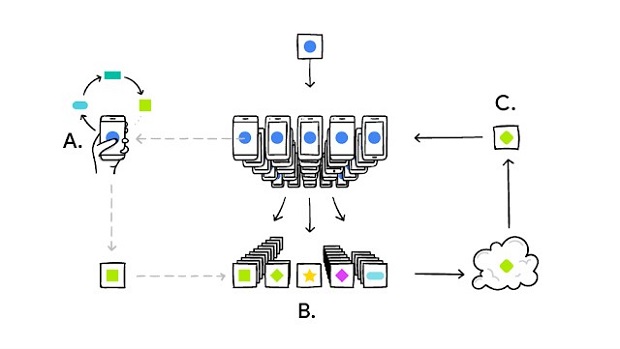
Cơ chế hoạt động của nó như thế này: thiết bị của bạn sẽ tải xuống mô hình hiện tại, cải thiện nó bằng cách học thông qua các dữ liệu từ trên điện thoại của bạn, và sau đó tổng hợp các thay đổi vào trong một bản cập nhật nhỏ. Chỉ có bản cập nhật này cho mô hình được gửi đến nền tảng đám mây, sử dụng cơ chế truyền thông được mã hóa, mà tại đó nó sẽ ngay lập tức được lấy trung bình với các bản cập nhật của những người dùng khác để hoàn thiện mô hình được chia sẻ chung. Tất cả các dữ liệu huấn luyện sẽ nằm trên thiết bị của bạn, và không có bất kỳ thông tin cá nhân nào được lưu trữ trên nền tảng đám mây.
(Nguồn: Google AI Blog)
Điện thoại của bạn sẽ cá nhân hóa mô hình một cách cục bộ, dựa trên hành vi của bạn (A). Nhiều bản cập nhật của người dùng sẽ được tổng hợp (B) để hợp thành một sự thay đổi đồng nhất (C) cho mô hình chung, sau đó quy trình này sẽ được lặp lại.
Thuật toán này phân tích các dữ liệu từ lịch sử duyệt web của bạn – các website bạn đã truy cập và nội dung của những trang này. Trớ trêu thay, đối với một công ty vận hành công cụ tìm kiếm tinh vi nhất thế giới thì quá trình đánh giá nội dung website cho FLoC lại rất cơ bản:
Cách tiếp cận đầu tiên của chúng tôi liên quan đến việc áp dụng thuật toán SimHash cho các tên miền của những website được truy cập bởi người dùng để phân cụm các người dùng truy cập những website tương tự lại với nhau. Các ý tưởng khác bao gồm việc bổ sung thêm các tính năng khác, chẳng hạn như đường dẫn đầy đủ của địa chỉ URL (full path URL) hoặc các danh mục (category) của các trang được cung cấp bởi một trình phân loại trên thiết bị (on-device classifier).
Amadan Evans – Chủ tịch của Closed Loop đã phát biểu rằng “Google và Facebook đã và đang triển khai các cơ chế tương tự trong những thuật toán đấu thầu của họ với nhiều thành công to lớn, vậy nên không có lý do gì mà FLoC lại không hiệu quả. Nhưng việc áp dụng phương pháp này bên ngoài Google sẽ yêu cầu khoản đầu tư đáng kể và chắc chắn sẽ có lợi cho những nền tảng quảng cáo (ad platform) lớn hơn với lượng lớn dữ liệu và tài nguyên.
Một FLoC ID sẽ bảo vệ người dùng dựa trên nguyên tắc “k ẩn danh”. Với số lượng “k” người dùng, danh tính của các cá nhân sẽ không thể biết được. (Các FLoC ID sử dụng những tên gọi định danh không mang tính mô tả, như “58B6” để ngăn không cho ID tiết lộ thông tin về người dùng).
Giá trị của “k” vẫn chưa được xác định. Các thử nghiệm được thực hiện bởi Google – bao gồm cả thử nghiệm chính mà họ trích dẫn để chứng minh tính hiệu quả của FLoC so với các nhóm tổ hợp ngẫu nhiên (“cải thiện 350% về khả năng ghi nhớ và 70% về độ chính xác”) – sử dụng giá trị “k” khoảng 5,000.
Trong khi đó, Allison Schiff – người đã từng viết nhiều bài viết về chủ đề FLoC cho AdExchanger nói rằng “Dù cho FLoC có hiệu quả hay không, thì nó cũng sẽ không thay thế được cho third-party cookies. Gần như không thứ gì có thể, bởi vì cookies, dù có không hoàn hảo, thì cũng có rất nhiều chức năng khác nhau. Vì thế nên FLoC có thể chỉ là một trong rất nhiều giải pháp thay thế cho chức năng nhắm mục tiêu mà cookie đang được sử dụng hiện nay.

Các cụm từ ngữ (word cluster) được hình thành dựa trên những thử nghiệm FLoC của Google với các giá trị “k” khác nhau.
Có một sự thật không quá bất ngờ, đó là giá trị “k” nhỏ hơn giúp cải thiện việc nhắm mục tiêu nhưng phải trả giá bằng tính ẩn danh; trong khi giá trị “k” cao hơn giúp cải thiện tính ẩn danh nhưng lại làm giảm tính chính xác của việc nhắm mục tiêu.
Evans tiếp tục, “Nếu một nhóm FLoC quá nhỏ, điều đó thể hiện cả các vấn đề liên quan đến bảo mật dữ liệu và các vấn đề tiềm ẩn về tính hiệu quả. Dù cho công nghệ máy học đã phát triển, nhưng chúng ta vẫn tiếp tục nhìn thấy những sai sót trong hiệu quả của công nghệ máy học đối với những nhà quảng cáo của những thị trường quá “ngách” hoặc những nhà quảng cáo có các tập dữ liệu nhỏ”.
Liệu chỉ ẩn danh có đủ không?
Việc ẩn danh người dùng không giải quyết tất cả vấn đề. Như một bài viết từ Electronic Frontier Foundation có trình bày:
Một định danh đại diện cho một tập hợp (flock name) về cơ bản sẽ là một điểm tín dụng về hành vi (behavioral credit score): một “hình xăm” trên “vùng trán digital” của bạn sẽ cung cấp một bản tóm tắt ngắn gọn bạn là ai, bạn thích gì, bạn đi đâu, bạn mua gì, và bạn có mối quan hệ với ai. Các định danh đại diện này có thể sẽ khó hiểu đối với người dùng, nhưng có thể tiết lộ những thông tin vô cùng nhạy cảm cho các bên thứ ba.
Arvind Narayanan – Giáo sư ngành khoa học máy tính tại Đại học Princeton cũng đồng thuận rằng:
Nếu một quảng cáo sử dụng các thông tin cá nhân kín để chi phối các điểm yếu về cảm xúc hoặc khai thác triệt để các khuynh hướng tâm lý để tạo ra hành vi mua hàng, thì đó là một hình thức xâm phạm quyền riêng tư, bất kể chi tiết về kỹ thuật có như thế nào.
Google đã thảo luận về các cách thức để loại trừ các dữ liệu “nhạy cảm” khỏi các dữ liệu đồng hóa đại diện (flock assignment), nhưng như họ thừa nhận, không có sự nhất trí nào cho tiêu chuẩn để được xem là “nhạy cảm”. Một tổ hợp FLoC có mối liên hệ với chủ đề “mang thai” sẽ mang một ý nghĩa đối với những đối tượng trên 30 tuổi nhưng lại là một câu chuyện khác đối với các học sinh trung học. Tính ẩn danh và tính bảo mật không phải là một.
Bạn có thể chọn không tham gia, và Chrome sẽ gửi một FLoC ngẫu nhiên thay vì một tổ hợp chính xác (thuật toán cũng có thể sẽ bổ sung thêm “độ nhiễu” bằng cách thỉnh thoảng gửi đi một FLoC ngẫu nhiên).
Các website cũng có thể chọn nếu không muốn được đưa vào các tổ hợp FLoC. Tuy nhiên, trong cả hai trường hợp thì mặc định sẽ là “Allow” (cho phép). Như Firefox đã lập luận, “chế độ mặc định chính là vấn đề”. Trước khi tính năng Bảo vệ theo dõi nâng cao (Enhanced Tracking Protection) của họ được đặt làm mặc định, thì chỉ có 20% người dùng bật nó lên.
Có những rủi ro khác đối với việc lạm dụng, nhất là đối với những website có quyền truy cập vào những thông tin nhận dạng cá nhân (PPI hay Personally Identificable Information):
Các website biết được thông tin PPI của một người (chẳng hạn như khi người dùng đăng nhập bằng cách sử dụng địa chỉ email) có thể lưu trữ lại và tiết lộ nhóm tổ hợp (cohort) của họ. Điều này có nghĩa là thông tin về các sở thích của một cá nhân cuối cùng có thể trở nên công khai.
Và không cách thức nào kể trên cho phép các marketer nhắm mục tiêu vào những đối tượng hiện có, chẳng hạn như những đối tượng đã bỏ quên giỏ hàng. Giải pháp cho vấn đề này phức tạp hơn – và gây nhiều tranh cãi.
Làm thế nào để bạn retarget một người dùng ẩn danh?
FLoC giúp cho các công ty nhắm mục tiêu người dùng dựa trên sở thích, dù cho họ có thể chưa boa giờ tương tác với website của công ty. Việc nhắm mục tiêu người dùng dựa trên những hành động quá khứ lại là một quy trình hoàn toàn khác.
Những nhóm người dùng này có thể đến từ một “danh sách người dùng” (user list), “danh sách tiếp thị lại” (remarketing list), “đối tượng tùy chỉnh” (custom audience”, hoặc “phân khúc thị trường dựa trên hành vi” (behavioral market segment). Thách thức cho các nhà quảng cáo là làm thế nào để nhắm mục tiêu vào các người dùng cá nhân mà không xuyên qua “bức màn” ẩn danh.
Giải pháp hiện tại là một loạt các đề xuất từ Google (TURTLEDOVE, DOVEKEY) và các “ad vendor” – nhà cung cấp quảng cáo (SPARROW, PARRROT, TERN). Sự cải tiến cốt lõi ở đây đó là khả năng lưu trữ dữ liệu xây dựng nên những danh sách này trong trình duyệt của người dùng hoặc với một bên thứ ba độc lập – không phải trên mạng quảng cáo (ad network).
Đề xuất “chim cu gáy” TURTLEDOVE: Nền tảng của một hệ thống mới
TURTLEDOVE lấy tên của một loài chim để đặt cho dự án và cũng là viết tắt của cụm từ “Two Uncorrelated Requests, Then Locally-Executed Decision On Victory.” (tạm dịch: “Hai yêu cầu không tương quan nhau, và quyết định được xử lý cục bộ để xác định quảng cáo chiến thắng”).
“Hai yêu cầu không tương quan nhau” được gửi từ trình duyệt (browser) đến mạng quảng cáo (ad network) – nơi hiển thị các mẫu quảng cáo, ở các thời điểm khác nhau để tránh bất kỳ mối liên hệ nào có thể được hình thành từ chúng:
- Contextual ad request: Một yêu cầu quảng cáo theo ngữ cảnh dựa trên địa chỉ URL (ví dụ như nytimes.com/nyc-marathon/) và bất kỳ thông tin nhắm mục tiêu nào của bên thứ nhất (chẳng hạn như dữ liệu người dùng từ những lần truy cập trước đây trên nytimes.com);
- Interest group ad request: Một yêu cầu tách biệt – không “dính dáng” gì đến page hiện tại hoặc dữ liệu người dùng – dựa trên mối quan tâm đã được nhà quảng cáo xác định trước đó “đẩy đến” cho trình duyệt.
Yêu cầu thứ hai có thể xảy ra trước khi một người dùng truy cập được vào trang nơi mà quảng cáo được phân phối, trình duyệt sẽ lưu thông tin quảng cáo vào bộ nhớ đệm cho đến khi được yêu cầu. Khoảng cách thời gian đó sẽ bảo vệ người dùng khỏi các “tấn công dự trên việc căn thời gian” (timing attacks) – một mạng quảng cáo (ad network) nhìn thấy cả 2 yêu cầu được gửi đến cùng một thời điểm và có thể sử dụng khoảng thời gian căn được đó để ghép các dữ liệu ngữ cảnh (contextual data) và dữ liệu sở thích (interest data) đó lại với nhau.
Trong phiên bản đầu tiên của TURTLEDOVE, trình duyệt của người dùng sau đó sẽ tổ chức phiên đấu thầu (dựa trên logic quyết định được đưa ra với hai yêu cầu đó). Vì phiên đấu thầu diễn ra trên trình duyệt của bạn và thiết bị của bạn, nên hai nguồn dữ liệu đó có thể được kết hợp để cải thiện việc đấu thầu mà không tiết lộ những thông tin của bạn cho các ad network.
(Sự kết hợp đó cho những người mua quảng cáo kiểm soát được nơi mà các quảng cáo của họ hiển thị – để một hãng hàng không sẽ không đang đấu thầu cho không gian quảng cáo trên một bài tin tức nói về một vụ tai nạn máy bay).
Bạn sẽ nhìn thấy quảng cáo có giá thầu cao nhất.
Dưới đây là một ví dụ từng bước về quy trình này:
- Bạn truy cập vào trang Article.com và lướt tìm các mẫu ghế sofa. Article.com chuyển thông tin về sở thích của bạn (ví dụ như “sofa nhiều ngăn”) đến trình duyệt của bạn thông qua một API mới. Đồng thời nó cũng cho một ad network, chẳng hạn như AdMatica quyền xem sở thích này.
- Tại một khoảng thời gian nào đó, trình duyệt sẽ yêu cầu các quảng cáo dựa trên nhóm sở thích (interest-group ads) từ AdMatica. AdMatica gửi đi các quảng cáo về sofa nhiều ngăn, bao gồm cả những nguyên lý cần thiết để tổ chức một phiên đấu thầu trên thiết bị. Trình duyệt web sẽ lưu trữ những thông tin này vào bộ nhớ đệm.
- Một thời gian sau đó, bạn truy cập cnn.com, trang này sử dụng nền tảng AdMatica để phân phối quảng cáo. Trình duyệt lúc này yêu cầu một quảng cáo dựa trên ngữ cảnh từ Admatica. Admatica trả về quảng cáo ngữ cảnh cũng như một yêu cầu tổ chức một phiên đấu giá trên thiết bị người dùng nếu hiện đang có một quảng cáo dựa trên sở thích rồi.
- Trình duyệt web tìm thấy quảng cáo dựa trên sở thích đã được lưu trong bộ nhớ đệm và tổ chức một phiên đấu thầu giữa quảng cáo đó và quảng cáo ngữ cảnh dựa trên nguyên lý đã được gửi đến từ nền tảng quảng cáo (ad platform).
- Trình duyệt sẽ tải xuống quảng cáo có giá thầu cao nhất.
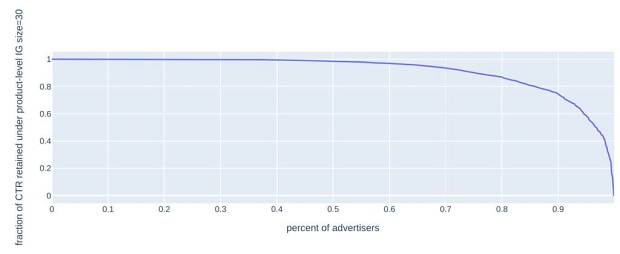
Một thử nghiệm của RTB House trên các quảng cáo sản phẩm cụ thể cho thấy rằng phương pháp này có thể hoạt động hiệu quả khi các nhóm sở thích bao gồm 30 người dùng. Thí nghiệm của họ ước tính rằng có 90% các nhà quảng cáo của họ sẽ giữ lại ít nhất 74% mức độ về tỉ lệ CTR hiện tại:
(Nguồn: Internet)
Dù vậy, đây vẫn là một thay đổi lớn. Hiện tại thì các phiên đấu thầu diễn ra trên các máy chủ ad network – với tất cả dữ liệu tích lũy về hành vi người dùng cùng với quyền truy cập trực tiếp vào những thuật toán đấu thầu của các nền tảng.
Việc chuyển dịch đấu thầu sang trình duyệt web sẽ yêu cầu các ad network cung cấp bất kỳ thử nghiệm nào về thuật toán cùng với hai yêu cầu không tương quan nhau. Các mạng quảng cáo (ad network) sẽ tìm hiểu và đúc kết thành quả của những thử nghiệm này chỉ từ báo cáo tổng hợp kết quả (đã bổ sung tín hiệu nhiễu).
Đó là một lý do làm cho các ad network không thích bản đề xuất ban đầu của TURTLEDOVE. Các phương án thay thế, chẳng hạn như SPARROW từ nền tảng Criteo, đã có những tranh biện về việc chuyển dịch hoạt động đấu thầu quảng cáo từ trình duyệt web sang một máy chủ thứ ba đáng tin cậy – có tên gọi “The Gatekeeper”. Và Google đã đồng thuận về quan điểm này.
“Chú chim sẻ” – SPARROW và “Người gác cổng” – The Gatekeeper
Tiếp tục đặt tên dự án theo một loài chim, đề xuất SPARROW chuyển hoạt động đấu thầu từ thiết bị của người dùng sang một máy chủ thứ ba. Sự thay đổi này khiến cho các ad network thuận tiện và dễ dàng hơn trong việc thử nghiệm A/B test các quảng cáo và tránh gửi đi gửi lại các thuật toán đấu thầu độc quyền của họ hàng triệu lần mỗi ngày (nó cũng giải quyết các vấn đề khác về đấu thầu trên thiết bị, chẳng hạn như tiêu hao pin điện thoại hoặc sử dụng hết dữ liệu di động).
Nhưng nó cũng “dỡ bỏ” đi một nguyên lý trọng tâm của TURTLEDOVE – đó là quá trình xử lý ẩn danh, nhạy cảm chỉ diễn ra trên thiết bị của bạn. Việc SPARROW có đáp ứng các mục tiêu về bảo mật dữ liệu hay không tùy thuộc vào việc bạn tin tưởng máy chủ thứ ba như thế nào, trên thực tế, là một bên thứ ba độc lập (và tất nhiên, là họ hoàn toàn có thể bị “hack”).
Trong kế hoạch đề xuất của SPARROW có trình bày chi tiết:
Các “người gác cổng” (tên gọi ẩn dụ cho các máy chủ thứ ba) phải độc lập với các bên khác trong hệ sinh thái công nghệ quảng cáo (ad tech ecosystem). Cụ thể, nền tảng DSPs không thể vận hành với vai trò “Gatekeeper” bởi vì những dịch vụ quảng cáo mà họ đang sở hữu.
Tính độc lập này có thể được đảm bảo bằng một thỏa thuận ràng buộc về mặt pháp lý và các thủ tục kiểm toán thích hợp. Một hiệp hội ngành, hoặc các cơ quan quản lý, có thể đảm bảo rằng những “Gatekeeper” sẽ hoàn thành nghĩa vụ của họ và có thể chứng nhận những “Gatekeeper” mới. Cuối cùng thì, trong trường hợp vi phạm hợp đồng, các nhà cung cấp trình duyệt sẽ là bên đưa “Gatekeeper” vào danh sách đen bởi vì các cơ hội hiển thị dựa trên sở thích được phân phối bởi các trình duyệt web đến các “Gatekeeper”.
Các “Gatekeeper” cung cấp một dịch vụ cho các nhà quảng cáo, chạy các mô hình của họ để tính toán giá thầu, và nên được các nhà quảng cáo trả tiền.
Đề xuất DOVEKEY của Google là một bước ngoặt của TURTLEDOVE và SPARROW. Nó chuyển vai trò của “Gatekeeper” – một máy chủ bên thứ ba – từ một bộ xử lý (processor) nguyên lý quảng cáo (ad logic) thành một bảng tra cứu (lookup table) đơn giản “sẽ lưu vào bộ nhớ cache các kết quả của logic đấu thầu và kiểm soát hiện có”.
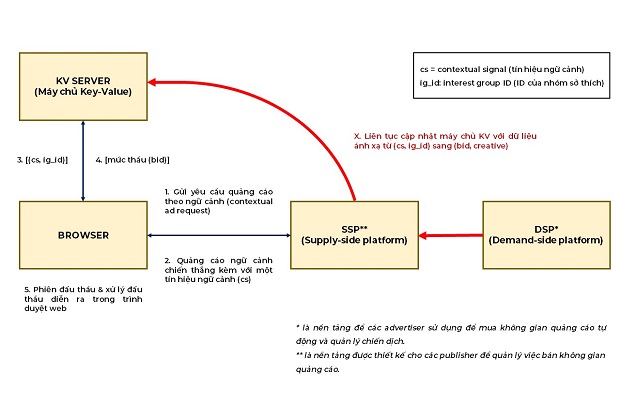
Với DOVEKEY, máy chủ của bên thứ ba đã giảm bớt vai trò: “một máy chủ Key-Value (KV) nhận một Key (là một tín hiệu ngữ cảnh kết hợp với một nhóm sở thích) và trả về một Value (mức giá thầu).”
Đề xuất trên làm yếu đi vai trò của tính ẩn danh, và trình bày rằng chỉ có ẩn danh khỏi các nhà quảng cáo mới là quan trọng:
Bởi vì máy chủ được tin cậy, vậy nên không có ràng buộc nào về hệ số k ẩn danh (k-anonymity) đối với yêu cầu này. Trình duyệt web cần tin tưởng rằng giá trị (value) mà máy chủ trả về cho mỗi đầu vào (key) sẽ chỉ được dựa trên đầu vào đó (key) và tên máy chủ (hostname), đồng thời máy chủ không ghi nhận dữ liệu về các sự kiện (no event-level logging) và cũng không có các tác động phụ nào khác dựa trên những yêu cầu này.
Việc triển khai thử nghiệm của hệ thống này, được gọi là FLEDGE đang diễn ra trong nửa đầu 2021, với các ad network sẽ đóng vai trò là “Gatekeeper” của riêng họ. Những thay đổi với cách quảng cáo được phân phối đã tạo nên những tác động mạnh mẽ, nhất là khi nói đến vấn đề báo cáo.
Các đề xuất theo dõi mới này có ảnh hưởng gì đến việc báo cáo?
(Nguồn: Internet)
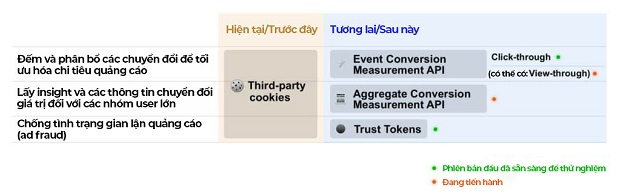
Giải pháp báo cáo chuyển đổi thời kỳ hậu third-party cookies được gọi là Conversion Measurement API. API này hoạt động bằng cách gắn các quảng cáo với các dữ liệu metadata (chẳng hạn như click ID, campaign ID, địa chỉ URL của chuyển đổi mong muốn…). Nếu một người dùng nhấp vào quảng cáo – thì metadata đó – có thể chứa đến 64 bit thông tin – sẽ được lưu trữ trong trình duyệt của họ.
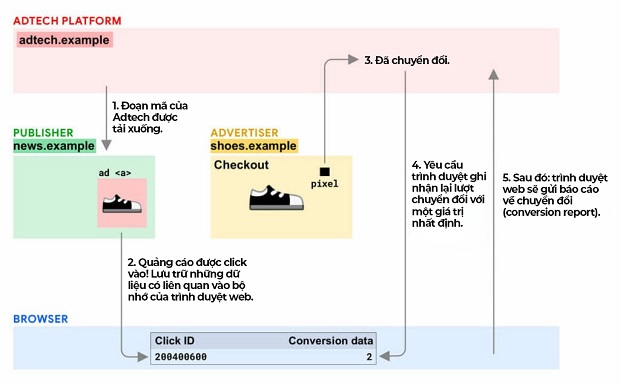
Cách mà cơ chế theo dõi chuyển đổi cho các quảng cáo có thể vận hành mà không có third-party cookies (Nguồn: Internet)
Nếu sau đó, họ chuyển đổi, thì trình duyệt của họ sẽ ghép nói dữ liệu của sự kiện chuyển đổi này với dữ liệu của lượt click vào quảng cáo (hiện tại không có giải pháp nào cho chuyển đổi dạng “view-through” – người dùng thấy quảng cáo nhưng không nhấp vào, nhưng sau đó hoàn thành một chuyển đổi trên website của bạn).
Dữ liệu ghi nhận chuyển đổi chỉ có 3 bit – đủ để xác định loại chuyển đổi đã xảy ra, không phải xác định người dùng đã chuyển đổi (trình duyệt Chrome thậm chí còn đề xuất bổ sung thêm các tín hiệu nhiễu bằng cách thỉnh thoảng gửi đi một giá trị 3-bit ngẫu nhiên).
Lượng dữ liệu được gửi cùng với lượt hiển thị quảng cáo hiện đang gây tranh cãi:
Đề xuất của Apple cho phép các marketer lưu trữ chỉ 6 bit thông tin trong một “campaign ID” (ID chiến dịch), nghĩ là một số từ từ 1 đến 64. Điều này là đủ để khác biệt hóa các quảng cáo cho các sản phẩm khác nhau, hoặc các chiến dịch sử dụng các phương tiện media khác nhau.
Ngược lại, trường ID của Google có thể chứa đến 64 bit thông tin – một con số từ 1 đến 18 tỷ tỷ. Điều này sẽ cho phép các nhà quảng cáo gán một ID riêng biệt cho từng và mỗi lượt hiển thị quảng cáo họ phân phối, và rất có thể là kết nối các lượt chuyển đổi quảng cáo với từng người dùng cá nhân. Nếu một người dùng tương tác với nhiều quảng cáo từ cùng một nhà quảng cáo trên web, thì những ID này có thể giúp cho nhà quảng cáo xây dựng một hồ sơ về thói quen lướt web của người dùng.
| Data |
Size |
Ví dụ |
| Click data | 64 bit | Ad ID hoặc Click ID (ID của quảng cáo hoặc lượt click) |
| Conversion data | 3 bit, có tín hiệu “nhiễu” (noised) | Một số nguyên từ 0 đến 7 có thể ánh xạ cho một loại chuyển đổi: đăng ký, hoàn tất thanh toán… |
Nhiều dữ liệu hơn được chuyển đi dựa trên lượt nhấp vào quảng cáo (hơn là dựa trên lượt chuyển đổi) để bảo vệ danh tính cá nhân.
Sau đó trình duyệt web sẽ lên lịch gửi một báo cáo về lượt chuyển đổi – theo ngày hoặc theo tuần để ngăn tình trạng phân tích thời gian thực thi (timing attack) có thể làm tiết lộ danh tính của dữ liệu.
Vậy nên, vài ngày hoặc vài tuần sau khi chiến dịch quảng cáo đang chạy, bạn mới có thể xem được những quảng cáo nào tạo ra nhiều lượt chuyển đổi nhất (và loại chuyển đổi mà chúng tạo ra). Nhưng bạn sẽ không thể đào sâu để xem những người dùng cá nhân nào chuyển đổi từ những quảng cáo nào.
Có những thách thức thực tế khác đối với kỷ nguyên hậu cookies – giống như việc đảm bảo rằng những người nhấp vào và chuyển đổi từ quảng cáo, trong thực tế, là những người thật.
Mã thông báo tin cậy (trust tokens)
Làm thế nào để bạn biết được những lượt click có đến từ người thật hay không? Trước đây, để xác định việc này cần phải có yêu cầu lấy “dấu vết” – tất cả các phương pháp để giải mã ẩn danh (chẳng hạn như thu thập dữ liệu về thiết bị của bạn, tùy chọn ngôn ngữ, tác nhân người dùng…) mà trình duyệt đó đang cố gắng để loại bỏ.
Giải pháp đề xuất của Google là một “mã thông báo tin cậy” (trust token). Các trust token đều “không được cá nhân hóa” và “không thể phân biệt được với nhau”, cho phép chúng có thể được chia sẻ mà không vi phạm về tính bảo mật.
Vậy ai sẽ là người phát hành các mã này? Chính là các website khác mà trên đó bạn đã thiết lập các thông tin về mình:
Bạn có thể có lịch sử mua sắm với một trang thương mại điện tử, check-in trên một nền tảng liên quan đến địa điểm, hoặc lịch sử tài khoản tại một ngân hàng. Các nhà phát hành cũng có thể nhìn vào các yếu tố khác chẳng hạn như thời gian bạn sở hữu tài khoản, hay các tương tác khác (chẳng hạn như mã CAPCHA hoặc hành động gửi biểu mẫu) làm tăng sự tin tưởng của nhà phát hành rằng bạn là một người thật.
Mặc dù FLoC và DOVEKEY đã tạo ra nhiều sự chỉ trích, nhưng ý tưởng về trust token đã được chào đón rộng rãi, và quyền sở hữu của Google đối với phần lớn thị trường CAPCHA sẽ giúp ích cho việc triển khai nó.
Tổng kết
Đại diện Chetna Bindra của Google đã chia sẻ với AdExchanger rằng các nhóm tổ hợp (cohorts) là “tương lai mà cơ chế nhắm mục tiêu hướng đến, ở một mức độ nào đó”.
Nếu những thay đổi lớn đang sắp sửa diễn ra, bạn nên làm gì bây giờ? Google gợi ý rằng bạn nên “triển khai gắn thẻ global site tag hoặc Google Tag Manager trên toàn trang web để giảm thiểu tối đa những gián đoạn trong thời gian này”.
Ngoài ra, một số chuyên gia cũng gợi ý tập trung vào dữ liệu của bên thứ nhất:
Hãy hành động ngay bây giờ thay vì “chờ đợi ngành công nghiệp tìm ra câu trả lời cho tất cả điều này”. Các dữ liệu bên thứ nhất (first-party data) sẽ là nền tảng của việc nhắm mục tiêu và đo lường quảng cáo kỹ thuật số, vậy nên các nhà quảng cáo nên bắt đầu bằng việc thu thập các dữ liệu first-party; phát triển các hệ thống và quy trình để có thể dễ dàng trích xuất và phân khúc dữ liệu; sau đó gửi nó về cho các nền tảng quảng cáo.
Các nhà quảng cáo chưa triển khai tính năng theo dõi chuyển đổi ngoại tuyến của Google (Google Offline Conversion Tracking) và Conversions API của Facebook nên chuẩn bị làm điều đó sớm nhất có thể.
HNAAu hi vọng bài viết đã cung cấp cho bạn những thông tin hữu ích về FLoC cùng những dự đoán về thay đổi sắp tới. Hãy cùng đón đọc những bài viết tiếp theo nhé!





ĐƠN VỊ TUYỂN DỤNG CHEFJOB.VN
ĐẦU BẾP - BẾP BÁNH - PHA CHẾ - PHỤC VỤ - BUỒNG PHÒNG
LỄ TÂN - QUẢN LÝ NHÀ HÀNG - KHÁCH SẠN
Hotline: 1900 2175 - Web: www.chefjob.vn
SIÊU THỊ ĐVP MARKET
Chuyên bán sỉ lẻ Nguyên liệu - Dụng cụ - Máy móc
TRÀ SỮA - CAFÉ - QUÁN ĂN - QUÁN KEM - KINH DOANH BÁNH
Hotline: 028 7300 1770 - Web: www.dvpmarket.com
Có (0) bình luận cho: FLoC Là Gì? Kế Hoạch Của Google Để Loại Bỏ Cookies Của Bên Thứ Ba
Chưa có đánh giá nào.