







































Wikidata là gì? Tại sao Wikidata lại cực kỳ quan trọng trong SEO?
Ở bài viết trước, chúng ta đã tìm hiểu về Machine ID. Hôm nay, Khóa học SEO Á Âu sẽ giới thiệu thêm cho bạn Wikidata là gì, cùng với một gợi ý nữa về cách sử dụng Machine-Readable Entity ID để có được quyền kiểm soát ngầm (back control) các dữ liệu quan trọng đối với doanh nghiệp của bạn và giúp những người khác có thể tìm đến bạn mà không có sự nhập nhằng nào về mặt ngữ nghĩa. Theo đó, hiệu quả của hoạt động SEO cũng sẽ tốt hơn.

Đối với nhiều người, thì Machine ID được xem là một chiến lược SEO cao cấp, nhưng bên cạnh đó, việc tạo ra và quản lý chúng cũng là một cách thức mới để làm Content Creation* và mang đến một “sức sống” mới cho hoạt động xây dựng liên kết theo kiểu truyền thống (traditional backlinking). Tuy nhiên để làm được điều đó thì chúng ta sẽ cần đến Wikidata và đó là lý do tại sao nền tảng này lại cực kỳ quan trọng để phát huy toàn bộ sức mạnh SEO tạo ra cho thực thể.
*Content Creation: Khác với sao chép nội dung, đây là hình thức sáng tạo nội dung bằng cách tham khảo & tổng hợp tài nguyên từ nhiều nguồn, kênh khác nhau, sau đó biên tập, chỉnh sửa và trình bày lại một cách phù hợp theo chủ đề đang khai thác.
Nhắc lại về khái niệm Machine ID
Machine ID hay Machine-Readable Entity ID (MREID) là ID của thực thể, đóng vai trò là một định danh duy nhất (unique identifier) cho một vật thể, một con người, một nơi chốn, hoặc một đối tượng mà máy có thể hiểu được. Thực thể có thể là các khái niệm trừu tượng như “lòng trắc ẩn” hoặc là một sự vật có tồn tại trong thực tế như Landmark 81.
(Nguồn: Internet)
Trước khi tìm hiểu cụ thể hơn, hãy tìm hiểu một chút về cách tổ chức tài nguyên trong các thư viện.
Cách thư viện tổ chức và quản lý các nội dung
Trong thế giới mà chúng ta đang sống, các kiến thức qua hàng thế kỷ đã được cô đọng lại trong những quyển sách và các quyển sách này đã được sắp xếp và quản lý trong các thư viện. Mỗi quyển sách trong thư viện đều sử dụng một mã code như 615.1 INT, và mã này tuân thủ theo một quy tắc gọi là Hệ thống phân loại thập phân Dewey (Dewey Decimal Classification). Hệ thống này sử dụng các con số từ 000 đến 999 để mô tả một lĩnh vực chủ đề cụ thể, ví dụ 300 cho Khoa học Xã hội (Social Science) và 700 cho Nghệ thuật & Giải trí (Arts & Recreation).
Các phần thập phân (decimal points) được dùng để phân loại sâu hơn vào một lĩnh vực kiến thức cụ thể, chẳng hạn như Dược lý (Pharmacology) sẽ được ký tự hóa thành mã 615.1. Ba ký tự tiếp theo đi sau con số này thường được lấy từ tên của quyển sách hoặc từ tác giả của nó. Số cốt (shelfmark) mà chúng ta thường thấy trong thư viện, nằm trên gáy của quyển sách cũng tương đương với khái niệm “Entity ID” trong thế giới World Wide Web.

(Nguồn: Internet)
Số cốt được dùng để phân loại các tài nguyên kỹ thuật số (hoặc để mô tả các sự vật tồn tại trong thế giới thực) trên Internet là các định danh mà máy có thể đọc được (machine ID) và được biểu diễn bằng URI (Universal Resource Identifier, là một chuỗi ký tự được sử dụng để xác định, nhận dạng một tên hoặc một tài nguyên).
Tìm hiểu về Wikidata
Wikidata cũng giống như một thư viện, và các dữ liệu có cấu trúc (structured data) giống với các quyển sách.
Wikidata là một cơ sở dữ liệu được liên kết miễn phí có thể được đọc và chỉnh sửa bởi cả con người và máy móc, đây là đầu mối cho tất cả dự án của Wikimedia bao gồm Wikipedia, Wikivoyage, Wikisource nhưng điều quan trọng nhất đó là nó có thể được kết nối với những bộ dữ liệu mở (open datasets) khác trên các trang có chứa dữ liệu liên kết (linked data) – đây là một phương thức để công bố các dữ liệu có cấu trúc sử dụng các bộ từ ngữ như Scheme.org, có thể liên kết được với nhau và với các dữ liệu khác để các máy có thể diễn giải và hiểu ý nghĩa của chúng.
Tại sao Wikidata lại quan trọng đối với SEO?
Các máy tìm kiếm như Google, Bing hay Yandex sử dụng Wikidata như là một trong những nguồn tài nguyên để trả lời cho những truy vấn của người dùng.
Wikidata cấu trúc thông tin trong một mạng lưới ngữ nghĩa (semantic network) bao gồm các thực thể (entity), các thuộc tính (attribute) và các mối liên hệ (relationship) cho phép một máy có thể khai thác một cơ sở tri thức khổng lồ về các dữ kiện. Đây là một cơ sở tri thức rất rộng lớn hoàn toàn được xây dựng dựa trên nền tảng dữ liệu liên kết từ cả các thông tin mà máy trích xuất được từ Wikipedia, các thông tin được cộng đồng đóng góp và các dữ liệu được tổng hợp tự động.
Wikidata được tổ chức ra sao?
Mô hình tổ chức dữ liệu của Wikidata được xây dựng dựa trên các thực thể (hay còn được gọi là “Items” trong Wikidata). Theo thông tin từ trang giới thiệu của Wikidata thì:
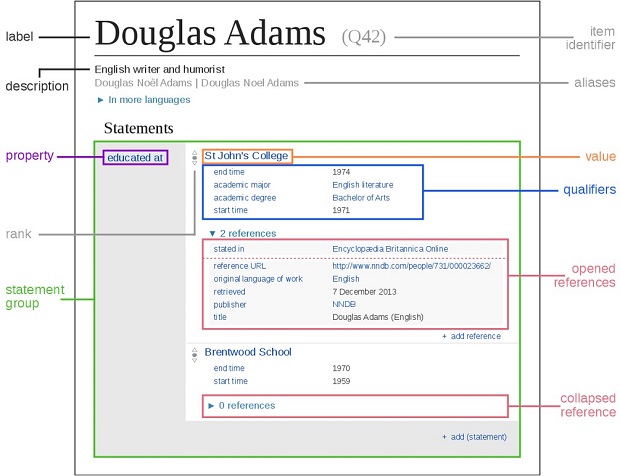
Kho lưu trữ của Wikidata chủ yếu bao gồm các item, mỗi một từ sẽ có một label, một description và nhiều aliases. Các mục từ được định danh duy nhất bằng tiền tố Q theo sau là một con số, ví dụ Douglas Adams (Q42).
Statements mô tả các đặc tính chi tiết của một Item và bao gồm một property và một value, trong mỗi value có thể chứa các qualifier hạn định những chi tiết liên quan đến value đó cùng với các reference tham chiếu cụ thể. Properties trong Wikidata sẽ bao gồm một tiền tố P theo sau là số, ví dụ như educated at (P69).
Đối với một danh mục về người, bạn có thể thêm một property để chỉ ra nơi họ từng học tập, bằng cách ghi một value cho trường học. Đối với công trình xây dựng, bạn có thể ghi một property tọa độ địa lý bằng cách điền các value vĩ độ và kinh độ. Các property cũng có thể liên kết đến các cơ sở dữ liệu bên ngoài. Một property dùng để liên kết với một cơ sở dữ liệu bên ngoài, ví dụ như cơ sở dữ liệu quản lý tác giả dùng trong các thư viện và viện lưu trữ, được gọi là một identifier. Các Sitelinks đặc biệt sẽ kết nối một item với nội dung tương ứng của nó trên các wiki, như Wikipedia, Wikibooks hoặc Wikiquote.
Tất cả những thông tin này sẽ được hiển thị bằng bất cứ ngôn ngữ nào, thậm chí khi dữ liệu được tạo ra bằng một ngôn ngữ khác. Khi truy cập các value này, các wiki sẽ hiển thị được thông tin mới nhất.
|
Item |
Property |
Value |
|
Q42 |
P69 |
Q691283 |
|
Douglas Adams |
educated at |
St John’s College |
Mọi người đều có thể đóng góp và có một danh sách rộng lớn bao gồm các đặc tính (properties) trong Wikipedia giúp chúng ta miêu tả các khái niệm quen thuộc. Lời khuyên là hãy bắt đầu quan sát những thực thể đang hiện có, xem kỹ phần hướng dẫn về Wikipedia tại địa chỉ https://www.wikidata.org/wiki/Wikidata:Tours hoặc tương tác với Wikidata Game https://tools.wmflabs.org/wikidata-game/distributed, nhưng trên hết, hãy luôn nhớ rằng Wikidata là một sáng kiến được xây dựng và phát triển dựa trên nền tảng cộng đồng và chất lượng của dữ liệu (data quality) là tối quan trọng.
Xây dựng backlink cho dữ liệu từ Wikidata
Backlink vẫn còn giữ được rất nhiều sức mạnh trong hoạt động SEO hiện nay. Số lượng, chất lượng và độ liên quan của backlink là một số yếu tố mà các máy tìm kiếm sử dụng để đánh giá một trang.
Khi đề cập đến những dữ liệu được công bố trong những cơ sở tri thức lớn như Wikidata hay DBpedia, thì mọi thứ đều tương đồng với nhau ở một mức độ nhất định. Một thực thể có thể được liên kết đến một thực thể tương đương trong một Sơ đồ tri thức khác miễn là nó được đăng tải và công bố dựa trên các nguyên lý của Dữ liệu Liên kết (Linked Data). Điều này là quan trọng bởi 2 lý do:
- Một máy (một trình thu thập thông tin, một ứng dụng hoặc phần mềm thông minh) có thể nhận thức được thực thể và có cơ sở rõ ràng để biết rằng chúng ta đang muốn nói đến cùng một khái niệm, một người, một vật hoặc một tổ chức…
- Một máy có thể thu thập thêm các thông tin (dưới dạng các statement) cho cùng thực thể đó.
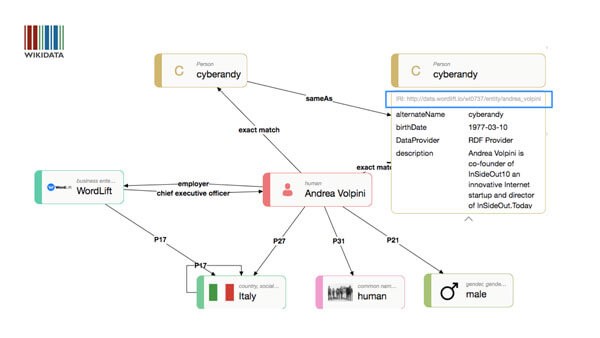
Hãy cùng xem qua một ví dụ về một thực thể tên là “Andrea Volpini” trên Wikidata.
(Nguồn: Internet)
Bạn có thể thấy trong hình ảnh minh họa này, thuộc tính exact_match có mã Property:P2888 trên Wikidata đang được sử dụng để tạo ra một liên kết giữa thực thể Andrea Volpini có mã Q28085380 (cũng trên Wikidata) và một thực thể về chính người này được tạo ra bằng WordLift và công bố nó dưới dạng dữ liệu liên kết tại địa chỉ http://data.wordlift.io/wl0216/entity/andrea_volpini.html.
Bằng cách này thì một máy có thể:
- Dễ dàng phân biệt người này với những thực thể có cùng tên gọi.
- Hiểu được rằng người này làm việc cho công ty WordLift (thông qua thuộc tính employer có mã Property:P108 trong Wikidata) và là bạn với một người tên là Teodora Petkova (thông qua liên kết tại mục schema:knows của thực thể Teodora tại địa chỉ http://data.wordlift.io/wl0216/entity/teodora_petkova).
Hai statement miêu tả mối liên hệ khác nhau (làm việc cho một đơn vị, và quen biết với một người nào đó) trong ví dụ này được suy ra từ hai cơ sở tri thức đã được kết nối với nhau theo cả hai chiều thông qua việc sử dụng thuộc tính exact_match của Wikidata và owl:sameAs (để kết nối với thực thể của Wikidata từ chính thực thể đó trên data.wordlift.io).
Ảnh hưởng của Machine-Readable ID lên Google Search
Google hiện đang sử dụng các MREID trong nhiều sản phẩm khác nhau như Google Trends, Google Maps, Google Lens và Google Image Search, nhưng trong số đó thì trải nghiệm người dùng trên Google Search bị ảnh hưởng sâu sắc nhất bởi MREID và các mạng lưới ngữ nghĩa được thiết lập đằng sau nó. Như đã trình bày ở phần Phụ lục 1 thì Google hiện tại đang sử dụng hai nhóm thực thể chính:
- Freebase Machine-Readable ID dành cho các thực thể được phát hiện và tạo ra khi Freebase vẫn còn hoạt động. Định dạng của ID này là: /m/[a-z0-9]+.
- Machine-Readable ID mới cho những thực thể được tạo ra trong thời kỳ hậu Freebase vơi định dạng /g/[a-z0-9]+.
6 bước để khai thác Machine ID hiệu quả trong SEO
Bước 1: Sử dụng các dữ liệu có cấu trúc trong các web page của bạn và tham chiếu đến (hoặc kết nối) các thực thể có dữ liệu liên kết, các thực thể trên Wikidata (Wikidata items) hoặc các mã MREID hiện tại từ Google bằng cách sử dụng thuộc tính schema:sameAs. Thực hiện tương tự với các trang mạng xã hội mà bạn đang sở hữu. Các máy tìm kiếm nhận diện các Profile trên mạng xã hội rất tốt và có thể suy ra nhiều thông tin hơn từ đó miễn là bạn đang cung cấp cho họ cơ sở rằng đây chính xác là thực thể đang được nói đến.
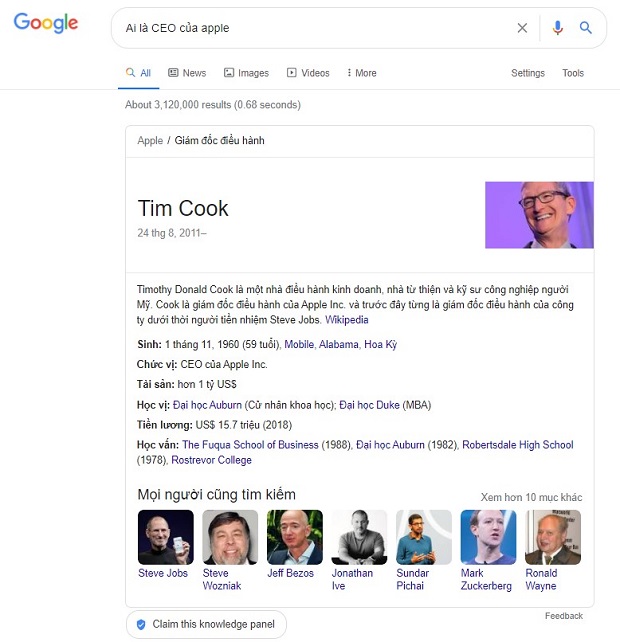
Như hình bên dưới, thì Google có thể biết được Tim Cook là CEO của Apple.
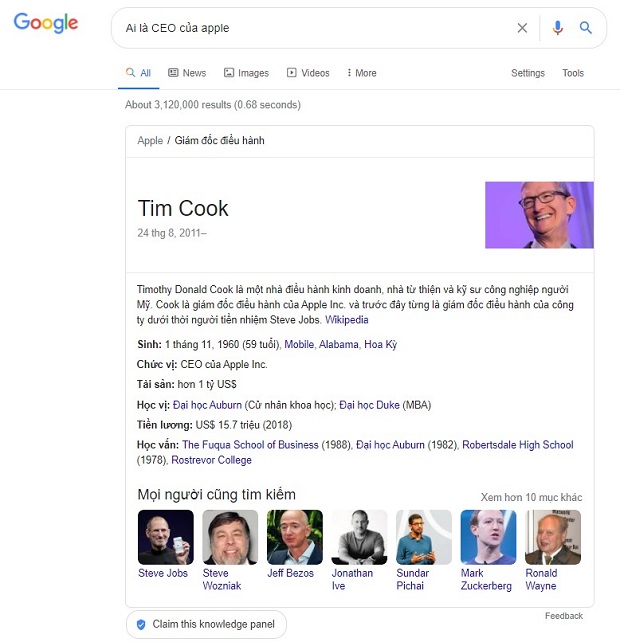
Đây là một trích dẫn nổi bật (featured snippet) được Google tạo ra từ tài khoản LinkedIn có các thông tin được xác nhận bởi các dữ liệu được công bố trên data.wordlift.io và Wikidata.
Các trích dẫn nổi bật cực kỳ dễ biến mất vì chúng thường dễ bị lỗi. Ngược lại, khi các dữ liệu được cung cấp đầy đủ trên những nguồn dữ liệu nổi tiếng, thì máy tìm kiếm sẽ dễ dàng tin tưởng tính xác thực của thông tin hơn và hiển thị chúng. Có một bằng sáng chế thú vị của Google trình bày rằng họ sẽ sử dụng mức độ tin cậy của cơ sở tri thức (Knowledge Base Trust) để đánh giá tính xác thực của một nội dung nào đó được lấy từ một website.
Bước 2: Nếu bạn là một thành viên của một doanh nghiệp hoặc một tổ chức, hãy tạo trang Google My Business và quản lý nó thật tốt.
Bước 3: Công bố các siêu dữ liệu metadata trong dữ liệu liên kết (linked data) bằng cách sử dụng WordLift hoặc bất kỳ công cụ nào giúp thực hiện chức năng đó. Đây là cách dễ dàng và thông dụng nhất để “giao tiếp” với các máy. Dữ liệu liên kết và Công nghệ Ngữ nghĩa (Semantic Technologies) mang đến một cách thức chính quy để công bố các thực thể (entity), các thuật ngữ (term), và các mối liên hệ (relationship) trong một lĩnh vực tri thức nào đó. Các máy tìm kiếm ngày càng phụ thuộc hơn vào các tính năng đột phá của trí tuệ nhân tạo (Artificial Intelligence hay AI), như các trích dẫn nổi bật trên Google, và yêu cầu các dữ liệu giàu tính thông tin về mặt ngữ nghĩa.
Bước 4: Lựa chọn những thực thể có ý nghĩa với bạn hay doanh nghiệp của bạn trên Wikipedia và Wikidata. Sử dụng thuộc tính exact_match Property:P2888 trên Wikidata để kết nối các thực thể mà bạn đã công bố dưới hình thức dữ liệu liên kết và đã đề cập đến chúng với các dữ liệu có cấu trúc trên website của mình.
Bước 5: Xác nhận thực thể trên Google. Cách đây 2 năm, Google đã giới thiệu tính năng cho phép các đối tượng được mọi người biết đến như con người, tổ chức, các đội thể thao, các sự kiện và các đơn vị truyền thông đại chúng… có thể được xác minh và đề xuất chỉnh sửa cho những thông tin được trình bày trên SERP. Đây là cách làm đơn giản và trực tiếp nhất để đề xuất những thay đổi sẽ được thực hiện trong Sơ đồ Tri thức Knowledge Graph của Google. Bạn có thể thực hiện việc này bằng cách nhấp vào dòng “Claim this knowledge panel” như hình bên dưới.
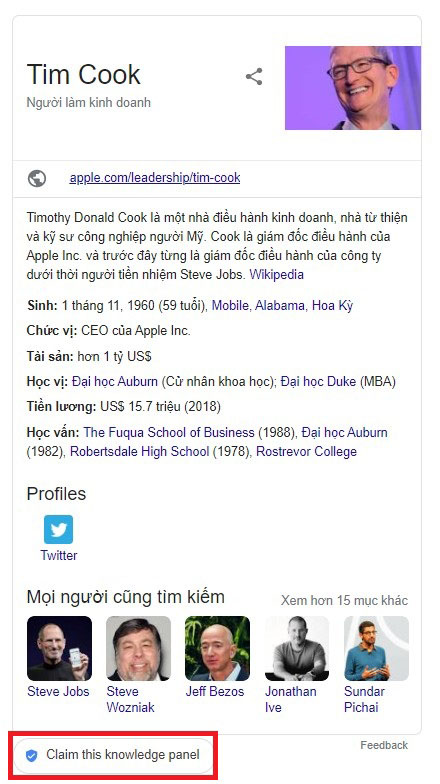
Sau đó bạn sẽ nhận được một email từ đội ngũ Google Search cho phép bạn đưa ra những đề xuất để giữ cho các dữ liệu này luôn được cập nhật mới nhất.

Bước 6: Hãy chú ý đến nhiều nguồn mà máy tìm kiếm có thể sử dụng để suy luận thêm kiến thức của nó và cố gắng hết sức để tuyển chọn ra những thực thể mà bạn quan tâm. Các trang danh bạ địa phương (local directories) như Yelp cực kỳ có giá trị bởi vì trang này được các máy tìm kiếm và các trợ lý cá nhân ảo như Apple Siri đánh giá là cực kỳ đáng tin cậy. Để làm cho máy có thể nhận diện được một thực thể xuất hiện trên nền tảng bên thứ ba một cách chính xác, hãy đảm bảo rằng các thông tin N.A.P: Name (tên), Address (địa chỉ), Phone (số điện thoại), mở rộng ra là N.A.P.E.W (E là Email và W là Website) luôn đồng bộ và giống với những dữ liệu đã được công bố trên website của bạn.
Với những kiến thức mới mẻ về MREID cùng với Wikidata, Hướng Nghiệp Á Âu mong rằng bạn sẽ ứng dụng thật hiệu quả để phát triển một chiến lược Entity SEO thật mạnh mẽ cũng như nâng cao thứ hạng cho doanh nghiệp của mình trong các kết quả tìm kiếm.






ĐƠN VỊ TUYỂN DỤNG CHEFJOB.VN
ĐẦU BẾP - BẾP BÁNH - PHA CHẾ - PHỤC VỤ - BUỒNG PHÒNG
LỄ TÂN - QUẢN LÝ NHÀ HÀNG - KHÁCH SẠN
Hotline: 1900 2175 - Web: www.chefjob.vn
SIÊU THỊ ĐVP MARKET
Chuyên bán sỉ lẻ Nguyên liệu - Dụng cụ - Máy móc
TRÀ SỮA - CAFÉ - QUÁN ĂN - QUÁN KEM - KINH DOANH BÁNH
Hotline: 028 7300 1770 - Web: www.dvpmarket.com
Có (0) bình luận cho: Wikidata là gì? Tại sao Wikidata lại cực kỳ quan trọng trong SEO?
Chưa có đánh giá nào.