







































Cách Google xác định phiên bản chính trong các duplicate content
Google Patent là một nguồn tài nguyên cực kỳ cao cấp và giá trị xoay quanh các công nghệ mà Google có khả năng sẽ áp dụng cho hệ thống tìm kiếm của mình. Trong bài viết hôm nay, hãy cùng Khóa học SEO Á Âu tìm hiểu xem khi có nhiều nội dung trùng lặp với nhau, thì Google sẽ xác định đâu là phiên bản chính và dựa trên cơ chế nào nhé!

Xác định các phiên bản chính của những trang trùng lặp
Google sẽ không phạt các trang có nội dung trùng lặp (duplicate pages) trên Internet, nhưng hệ thống có thể cố gắng xác định xem phiên bản nào được ưu tiên hơn trong số những trang trùng lặp.
Có một nhận định được đưa ra bởi công ty Dejan SEO về vấn đề các trang trùng lặp:
“Nếu có nhiều phiên bản giống nhau của cùng một tài liệu trên Internet, thì địa chỉ URL nào có độ uy tín cao nhất sẽ trở thành phiên bản chính thống (canonical). Tất cả các địa chỉ còn lại đều sẽ được xem là bản sao.”
Nhận định trên được trích ra từ bài viết: Link inversion, the least known major ranking factor (tạm dịch: Đảo nghịch liên kết [1] – một yếu tố xếp hạng quan trọng ít được biết đến nhất). Và có một bằng sáng chế của Google có liên quan đến yếu tố “authority” (độ uy tín) tên là Identifying a primary version of a document (tạm dịch: Xác định phiên bản chính của một tài liệu). Văn bằng này không trình bày những nội dung như công ty Dejan đã mô tả, nhưng điều thú vị là nó đưa ra những cách thức để phân biệt giữa những trang trùng lặp trên những tên miền khác nhau dựa trên những quy tắc về sự ưu tiên, và đây lại là một tiêu chí giá trị trong việc xác định xem trang nào trong số những trang giống nhau có thể là địa chỉ URL có độ uy tín cao nhất đối với một tài liệu nhất định.
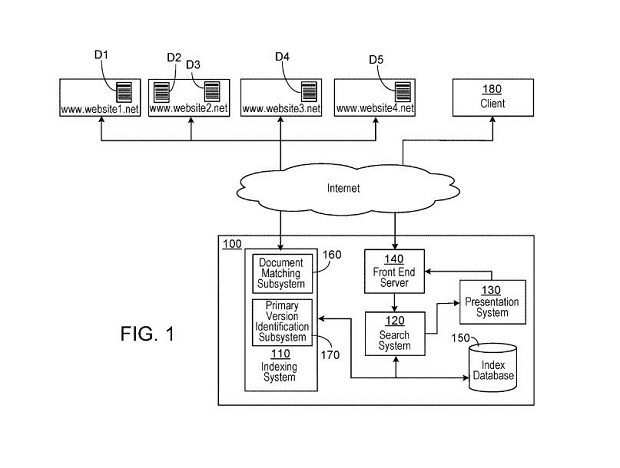
(Nguồn: Google)
Phần tóm tắt của bằng sáng chế này trình bày rằng:
“Một hệ thống và phương pháp giúp xác định phiên bản chính trong số các phiên bản khác nhau của cùng một tài liệu. Hệ thống này sẽ lựa chọn một mức độ uy tiên về độ uy tín cho từng phiên bản của tài liệu dựa trên một quy tắc ưu tiên được thiết lập và các thông tin gắn liền với phiên bản tài liệu đó, từ đó chọn ra một phiên bản chính dựa trên sự ưu tiên về độ uy tín và các thông tin gắn liền với phiên bản tài liệu này.”

(Nguồn: Internet)
Các nhà thẩm định bằng sáng chế tại Cơ quan sáng chế và nhãn hiệu Liên bang Mỹ USPTO sẽ nhìn vào các nhận định rút ra được khi xem xét một bằng sáng chế và quyết định xem văn bằng đó có nên được cấp phép hay không. Nhận định đầu tiên trong bằng sáng chế đã trình bày một số nội dung giúp mở ra những hướng suy nghĩ khả thi khi đề cập đến những phiên bản khác nhau của những trang trùng lặp, và cách mà những siêu dữ liệu (metadata) gắn liền với một tài liệu cụ thể được xem xét để xác định xem đâu là phiên bản chính của một tài liệu:
“1. Một phương pháp bao gồm:
sử dụng một hệ thống máy tính để xác định nhiều phiên bản khác nhau của một tài liệu;
sử dụng hệ thống máy tính đó, xác định loại metadata đầu tiên gắn liền với từng phiên bản tài liệu trong số nhiều phiên bản, và loại metadata này sẽ bao gồm các dữ liệu giúp mô tả về nguồn (source) của một phiên bản tài liệu tương ứng;
sử dụng hệ thống máy tính để xác định loại metadata thứ hai gắn liền với từng phiên bản tài liệu trong số nhiều phiên bản, và loại metadata thứ hai đó là dữ liệu mô tả về một đặc tính (feature) nào đó của từng phiên bản tài liệu, ngoại trừ nguồn của chúng;
sử dụng hệ thống máy tính để áp dụng một quy tắc ưu tiên đối với loại metadata đầu tiên và loại metadata thứ hai cho từng phiên bản tài liệu trong số nhiều phiên bản này, để tạo ra một điểm số thể hiện giá trị ưu tiên (priority value);
sử dụng hệ thống máy tính để chọn ra một phiên bản tài liệu trong số nhiều phiên bản dựa trên các giá trị ưu tiên được tạo ra cho từng tài liệu trong số các phiên bản tài liệu khác nhau này;
và sử dụng hệ thống máy tính để cung cấp một phiên bản tài liệu được dùng để hiển thị trong các kết quả trả về.”
Nhưng điều này không cổ xúy cho nhận định rằng phiên bản chính (primary version) của một tài liệu sẽ được xem là phiên bản chính thống (canonical version) của tài liệu đó, và tất cả các liên kết trỏ đến tài liệu đó đều được chuyển hướng về phiên bản chính. Cần phải làm rõ được sự khác biệt này.
Có một bằng sáng chế khác có cùng nhà phát minh với bằng sáng chế này tên là Representative document selection for a set of duplicate documents (tạm dịch: Lựa chọn một tài liệu đại diện trong số các tài liệu trùng lặp) đề cập đến việc một trong số các địa chỉ URL có nội dung trùng lặp sẽ được chọn như là một trang đại diện (representative page), dù trong đó tác giả không sử dụng thuật ngữ “canonical” (chính thống). Dưới đây là một phần nội dung trích ra từ bằng sáng chế đó:
“Các tài liệu trùng lặp, có cùng nội dung giống nhau, được nhận diện bởi một hệ thống quét dữ liệu website. Khi tiếp nhận một tài liệu vừa mới được quét, thì một tập hợp các tài liệu trong số các tài liệu được quét trước đó có cùng nội dung với tài liệu vừa mới được quét này sẽ được nhận diện (nếu có). Các thông tin giúp nhận diện tài liệu vừa mới được quét này và một tập hợp các tài liệu đã được chọn ra được hợp nhất thành các thông tin giúp nhận diện một tập hợp các tài liệu mới. Các tài liệu trùng lặp được bao hàm hoặc loại ra khỏi tập tài liệu mới này dựa trên một chỉ số độc lập với truy vấn (query-independent metric) được xác định cho mỗi tài liệu như thế. Một tài liệu được chọn làm đại diện duy nhất cho tập các tài liệu mới sẽ được xác định dựa trên một tập hợp các điều kiện đã được định trước.
Trong một số trường hợp, một phương pháp dùng để lựa chọn một tài liệu làm đại diện từ một tập hợp các tài liệu trùng lặp sẽ bao gồm: lựa chọn ra một tài liệu hàng đầu trong số nhiều tài liệu căn cứ trên việc tài liệu hàng đầu này gắn liền với một mức điểm số độc lập với truy vấn (query-independent score), theo đó mỗi tài liệu tương ứng trong số nhiều tài liệu đều có một dấu vân (fingerprint) giúp nhận diện nội dung của chúng, dấu vân này của từng tài liệu chỉ ra rằng mỗi tài liệu đó có nội dung tương đồng đáng kể với mỗi tài liệu khác trong số nhiều tài liệu, và một tài liệu hàng đầu trong số nhiều tài liệu này sẽ gắn liền với một mức điểm số độc lập với truy vấn. Ngoài ra, phương pháp này còn bao gồm việc lập chỉ mục cho tài liệu hàng đầu đó, dựa trên điểm số độc lập với truy vấn; và trong số nhiều tài liệu trùng lặp với nhau, thì chỉ có tài liệu hàng đầu được lập chỉ mục đó được đưa vào trong chỉ mục tài liệu [2].
Bất kể việc phiên bản chính trong một tập hợp các trang trùng lặp có được xem là tài liệu đại diện như được trình bày trong bằng sáng chế thứ hai này hay không, thì điều quan trọng là cần hiểu rõ được cơ chế và bản chất của một phiên bản được chọn làm tài liệu chính.
Trong đoạn trích lớn ở trên, có một số khái niệm cần được giải thích cụ thể hơn. Chẳng hạn như “điểm số độc lập với truy vấn” (query-independent score), hay còn gọi là “điểm tài liệu” (document score) cho mỗi địa chỉ URL, sẽ được tính toán bởi các máy tính điểm page rank cho URL. Điểm số này không chỉ dựa trên số lượng địa chỉ URL có đề cập đến một địa chỉ URL cụ thể, mà còn dựa trên page rank của các địa chỉ tham chiếu (referencing URL) đó.
Bên cạnh đó, trong phạm vi bằng sáng chế này, để đơn giản hóa thì đôi khi các khái niệm “web page”, “page content”, “URL” và “page rank” sẽ được sử dụng thay cho các thuật ngữ có tính tổng quát hơn như “tài liệu” (document) hay “nội dung tài liệu” (document content), “địa chỉ tài liệu” (document address) và “điểm số tài liệu” (document score), theo thứ tự tương ứng. Dựa trên hình thức và nội dung của chúng, một web page được quét qua nhìn chung thường sẽ rơi vào ít nhất một trong 3 nhóm sau:
- Một trang chuyển hướng vĩnh viễn (permanent redirect, hay chuyển hướng 301) bao gồm địa chỉ URL nguồn (source URL) và địa chỉ URL của trang mục tiêu (target URL), nhưng không chứa nội dung (ở đây được hiểu là “page content”) của địa chỉ URL mục tiêu;
- Một trang chuyển hướng tạm thời (temporary redirect, hay chuyển hướng 302) bao gồm địa chỉ URL nguồn và địa chỉ URL mục tiêu cũng như nội dung trên trang của địa chỉ URL mục tiêu, và một số điểm không phụ thuộc vào truy vấn (page rank) cho địa chỉ URL nguồn;
- Một trang web page thông thường bao gồm địa chỉ URL, nội dung trên trang và một mức điểm số.

(Nguồn: Search Engine Journal)
Chuyển hướng vĩnh viễn là một dấu hiệu cho thấy một địa chỉ URL không còn được sử dụng nữa và được thay thế bằng một địa chỉ URL khác. Sau khi tiếp nhận một trang chuyển hướng vĩnh viễn, thì bọ quét sẽ không lần theo lệnh chuyển hướng vĩnh viễn được tìm thấy trong địa chỉ URL nguồn để truy cập vào địa chỉ URL mục tiêu. Thay vào đó, nó sẽ chuyển thông tin về việc chuyển hướng vĩnh viễn này cho các bộ lọc nội dung (content filters). Song song với việc nhập thông tin về việc chuyển hướng vĩnh viễn, thì các bộ lọc nội dung còn yêu cầu máy chủ nhận diện trang trùng lặp (Dupserver) thay thế các URL fingerprint [3] của những đường link được chuyển hướng vĩnh viễn ra bên ngoài (permanently redirected out-going links) trong số các trang được tải về hệ thống bằng các URL fingerprint của các địa chỉ URL mục tiêu mà các chuyển hướng vĩnh viễn này hướng đến.
Ngược lại, chuyển hướng tạm thời là một dấu hiệu cho thấy một địa chỉ URL đã tạm thời được thay thế bởi một địa chỉ URL khác. Chuyển hướng tạm thời không chỉ ra địa chỉ URL nào (địa chỉ nguồn hoặc mục tiêu) là địa chỉ được ưu tiên hơn đối với một trang. Sau khi tiếp nhận một trang được chuyển hướng tạm thời, thì bọ quét sẽ lần theo chuyển hướng tạm thời đó và ghi nhận các nội dung trên trang. Hầu hết các địa chỉ URL được quét qua bởi các bọ đều là các web page thông thường (regular web page), bao gồm một địa chỉ URL và nội dung trên trang đó. Mỗi trang được quét qua sẽ được gán cho một điểm số tài liệu (document score), thể hiện mức độ quan trọng (importance) hoặc độ phổ biến (popularity) của trang. Điểm số này (page rank) được ghi nhận trước khi địa chỉ URL được tải về bởi bọ quét và chuyển thông tin cho những đơn vị có liên quan để xử lý trong hệ thống.
Về các tài liệu trùng lặp (duplicate documents) thì đây là những tài liệu có sự tương đồng đáng kể về nội dung, hoặc giống nhau hoàn toàn, nhưng có những địa chỉ tài liệu (document addresses) khác nhau. Theo đó, có ít nhất ba trường hợp mà một bọ quét có thể gặp phải khi quét qua các tài liệu trùng lặp:
- Hai trang, bao gồm bất kỳ tổ hợp nào giữa (các) web page thông thường và (các) trang chuyển hướng tạm thời, là các tài liệu trùng lặp nhau nếu chúng có cùng một nội dung, nhưng có địa chỉ URL khác nhau;
- Hai trang chuyển hướng tạm thời là các tài liệu trùng lặp nhau nếu chúng có cùng một địa chỉ URL mục tiêu, nhưng có những địa chỉ URL nguồn khác nhau;
- Một trang web page thông thường và một trang chuyển hướng tạm thời là các tài liệu trùng lặp nhau nếu địa chỉ URL của web page đó là địa chỉ URL mục tiêu của trang chuyển hướng tạm thời hoặc nội dung của web page đó giống với nội dung của trang chuyển hướng tạm thời.
Một trang chuyển hướng tạm thời không liên quan trực tiếp đến quá trình xác định tài liệu trùng lặp vì bọ quét được cấu hình để không tải về nội dung của trang mục tiêu trong trường hợp này.
Lý do một phiên bản trong số nhiều trang trùng lặp có thể được lựa chọn làm phiên bản chính
Bằng sáng chế về vấn đề này đã đưa ra một số lý do tại sao một trong số các trang trùng lặp có thể được xem như là phiên bản chính:
(1) Việc bao hàm nhiều phiên bản khác nhau của cùng một tài liệu không mang lại thêm thông tin hữu ích, và nó cũng không tạo ra giá trị cho người dùng.
(2) Các kết quả tìm kiếm bao hàm các phiên bản khác nhau của cùng một tài liệu có thể lấn át và chiếm chỗ của những nội dung đa dạng khác lẽ ra nên được đưa vào.
(3) Khi có nhiều phiên bản khác nhau của một tài liệu được hiển thị trong các kết quả tìm kiếm, thì người dùng có thể không biết được đâu là phiên bản hoàn chỉnh, có độ uy tín cao nhất hoặc tốt nhất để truy cập, và do đó có thể làm họ lãng phí thời gian khi phải truy cập vào các phiên bản khác nhau để so sánh các trang này.
Trên đây là ba lý do mà bằng sáng chế về các trang trùng lặp đưa ra để giải thích cho việc cần phải xác định phiên bản chính trong số nhiều phiên bản tài liệu khác nhau có trên Internet. Máy tìm kiếm hoạt động với mục tiêu cung cấp cho người dùng “kết quả tìm kiếm phù hợp và đáng tin cậy nhất”.
Cơ chế hoạt động
Bằng sáng chế này trình bày một phương pháp giúp xác định phiên bản chính như sau.
Các phiên bản khác nhau của một tài liệu được xác định từ nhiều nguồn khác nhau, chẳng hạn như các cơ sở dữ liệu trực tuyến, các website và các hệ thống dữ liệu thư viện.
Đối với mỗi phiên bản tài liệu, sự ưu tiên về độ uy tín sẽ được chọn lựa dựa trên:
(1) Thông tin về siêu dữ liệu (metadata) gắn liền với phiên bản tài liệu đó, chẳng hạn như:
- Nguồn (source)
- Quyền sở hữu tác quyền được độc quyền xuất bản (exclusive right to publish)
- Quyền cấp phép (licensing right)
- Thông tin trích dẫn (citation information)
- Các từ khóa (keywords)
- Page rank
- Và những thông tin tương tự
(Nguồn: Ontotext)
(2) Bước thứ hai, các phiên bản của tài liệu sau đó sẽ được đánh giá xem có đáp ứng được tiêu chuẩn về độ dài (length qualification) hay không. Phiên bản nào có sự uy tiên về độ uy tín cao và độ dài đáp ứng được tiêu chuẩn sẽ được xem là phiên bản chính của tài liệu đó.
Nếu không có phiên bản tài liệu nào vừa có độ ưu tiên cao vừa đáp ứng được độ dài tiêu chuẩn, thì phiên bản chính sẽ được lựa chọn dựa trên toàn bộ thông tin gắn liền với từng phiên bản tài liệu.
Bằng sáng chế cũng trình bày rằng các tác phẩm học thuật (scholarly works) có xu hướng sẽ được áp dụng quy trình này:
“Bởi vì các tác phẩm có tính học thuật phải tuân thủ các yêu cầu nghiêm ngặt về định dạng, nên các tài liệu chẳng hạn như các bài viết cho tập san (journal articles), các bài viết cho hội thảo (conference articles), các bài nghiên cứu khoa học (academic papers) và các danh mục trích dẫn (citation records) của những tài liệu này sẽ chứa các thông tin về dữ liệu metadata giúp mô tả nội dung và nguồn của tài liệu đó. Theo đó, các tác phẩm có tính học thuật sẽ là những tài nguyên “sáng giá” nhất được áp dụng trong hệ thống nhận diện này.”
Các siêu dữ liệu (meta data) được xem xét trong quá trình này có thể bao gồm:
- Tên của các tác giả (author names)
- Tiêu đề (title)
- Đơn vị xuất bản (publisher)
- Ngày xuất bản (publication date)
- Địa chỉ xuất bản (publication location)
- Các từ khóa (keywords)
- Page rank
- Thông tin trích dẫn (citation information)
- Các định danh số (article identifiers) cho bài viết như Digital Object Identifier, PubMed Identifier, SICI, ISBN, và những loại như thế.
- Địa chỉ mạng (network location, chẳng hạn như địa chỉ URL)
- Số lượng tham chiếu/đề cập (reference count)
- Số lượng trích dẫn (citation count)
- Ngôn ngữ (language)
- Và các dữ liệu tương tự khác
Bằng sáng chế về các trang trùng lặp còn trình bày sâu hơn về phương pháp luận được áp dụng trong việc xác định phiên bản chính của một tài liệu:
“Quy tắc về sự ưu tiên (priority rule) tạo ra một giá trị số học (một điểm số) để phản ánh về mức độ uy tín/độ thẩm quyền (authoritativeness), mức độ hoàn chỉnh (completeness), hoặc mức độ tốt nhất (best to access) để một người dùng truy cập vào của một phiên bản tài liệu. Cụ thể, quy tắc ưu tiên xác định sự ưu tiên về độ uy tín được gán cho một phiên bản tài liệu song song với nguồn của phiên bản tài liệu đó dựa trên một danh sách ưu tiên về nguồn (source-priority list). Danh sách này bao gồm một danh mục các nguồn, mỗi nguồn sẽ có sự ưu tiên về độ uy tín tương ứng. Sự ưu tiên của một nguồn có thể được xác định dựa trên sự lựa chọn có liên quan đến các yếu tố trong quá trình biên tập (editorial selection), bao gồm việc xem xét các yếu tố ngoại lai (extrinsic factors) như danh tiếng của nguồn đó (reputation), kích thước corpus [4] của xuất bản phẩm của nguồn (size of source’s publication corpus), tính chất vừa xảy ra trong khoảng thời gian gần đây (recency) hoặc tần suất cập nhật (frequency of updates), hoặc bất kỳ yếu tố nào khác. Mỗi phiên bản tài liệu theo đó sẽ gắn liền với một mức độ ưu tiên về uy tín; và sự liên kết này có thể được lưu trữ trong một cấu trúc bảng (table), cấu trúc hình cây (tree) hay các cấu trúc dữ liệu khác.”
Bằng sáng chế cũng bao gồm một số phương pháp thay thế, trình bày rằng “thước đo về độ ưu tiên để xác định xem một phiên bản tài liệu có đạt được tiêu chuẩn về độ uy tín hay không có thể được dựa trên giá trị chuẩn về độ ưu tiên”.
“Giá trị chuẩn về độ ưu tiên (qualified priority value) là một ngưỡng để xác định xem một phiên bản tài liệu có đầy đủ/hoàn chỉnh, có uy tín/thẩm quyền hay dễ dàng truy cập hay không, tùy thuộc vào quy tắc ưu tiên. Khi sự ưu tiên được gán cho một phiên bản tài liệu lớn hơn hoặc bằng với giá trị chuẩn về độ ưu tiên, thì tài liệu đó sẽ được xem là đầy đủ/hoàn chỉnh, có uy tín hoặc dễ dàng truy cập, tùy thuộc vào quy tắc ưu tiên. Ngoài ra, giá trị chuẩn về sự ưu tiên có thể được xác định dựa trên sự so sánh lẫn nhau, chẳng hạn như trong số các giá trị về độ ưu tiên dành cho một tập hợp các phiên bản tài liệu, thì mức độ ưu tiên cao nhất sẽ được chọn làm độ ưu tiên chuẩn.”
Tổng kết
Bằng sáng chế được đề cập đã trình bày chi tiết hơn về vấn đề xác định xem trang nào trong số các trang trùng lặp sẽ được lựa chọn làm tài liệu chính. Tuy nhiên chúng ta không thể biết được rằng liệu tài liệu chính đó có được xem như là địa chỉ URL chính thống (canonical URL) trong số tất cả tài liệu trùng lặp như đã được gợi ý trong bài viết của công ty Dejan SEO hay không, nhưng điều thú vị là chúng ta có thể tham khảo được cách thức mà Google quyết định xem phiên bản nào của tài liệu sẽ được chọn làm phiên bản chính.
________________________
Chú giải:
[1] Hay link inversion, thuật ngữ miêu tả quá trình các backlink đang trỏ đến các trang bản sao (duplicates) bị “đảo ngược” và trỏ về địa chỉ URL chính thống (canonical URL).
[2] document index (thuật ngữ gốc), dùng để miêu tả một cơ sở dữ liệu chứa vị trí của tất cả các đầu mục (entry) hay các từ/từ khóa trong một nhóm các tài liệu ngoại trừ các từ gây nhiễu (ví dụ như “nhưng” (but) và “nếu” (if).
[3] là những “dấu vân”, những đặc điểm giúp nhận diện một địa chỉ URL.
[4] đây là thuật ngữ mô tả một tập hợp các văn bản, ngôn ngữ đã được số hóa.


ĐƠN VỊ TUYỂN DỤNG CHEFJOB.VN
ĐẦU BẾP - BẾP BÁNH - PHA CHẾ - PHỤC VỤ - BUỒNG PHÒNG
LỄ TÂN - QUẢN LÝ NHÀ HÀNG - KHÁCH SẠN
Hotline: 1900 2175 - Web: www.chefjob.vn
SIÊU THỊ ĐVP MARKET
Chuyên bán sỉ lẻ Nguyên liệu - Dụng cụ - Máy móc
TRÀ SỮA - CAFÉ - QUÁN ĂN - QUÁN KEM - KINH DOANH BÁNH
Hotline: 028 7300 1770 - Web: www.dvpmarket.com
Có (0) bình luận cho: Cách Google xác định phiên bản chính trong các duplicate content
Chưa có đánh giá nào.